Обзор лучших докладов HighLoad++ 2018 (#2 серия)
Предлагаем вам продолжение обзора лучших докладов HighLoad++ 2017 от Романа Ивлиева (видео прилагается):
- Fraud in mobile applications: how to define and detect.
- Делаем свою прошивку для IP-камеры на Rust.
- BigПочта: как мы строили DataLake в Почте России.
- Дешевле, надёжнее, проще. Хранение петабайтов видео и фото в ОК.
Вадим Антонюк (IPONWEB). Fraud in mobile applications: how to define and detect
Почётное третье место. Вадим не первый раз рассказывает про антифрод на Highload++. Годом ранее его рассказ был посвящен вопросам антифрода в RTB-системах в целом, в этот раз «досталось» мобильным приложениям. Забегая вперёд, скажу, что до сих пор идут споры о том, что считать фродом именно в мобильных приложениях, в отличие от веба, где всё более-менее понятно. Тем не менее, сегмент растёт, проблема вместе с ним растёт, а значит, самое время начать ее решать, «пока не началось».

Между тем, если вы не знаете или все еще сомневаетесь, что RTB — это хайлоад, — как вам цифра в 400 миллиардов запросов в сутки? При этом по статистике на долю мобильных приложений приходится около 40% — больше, чем на десктопный веб. IPONWEB (один из крупных игроков рынка RTB-рекламы) достаточно давно и успешно детектирует фрод в веб-сегменте, но до приложений добрались только вот-вот.
Итак. Классические методы (боты, AdStackng, Domains Spoofing, Ghost sites), которые давно применяются в классическом вебе, в мобильных приложениях в явном виде не работают. Как следствие, не подходят и методы борьбы с ними, и нужно изобретать что-то новое.
Кстати, индустрия еще не договорилась о том, что считать фродом в мобильных приложениях. Казалось бы, истории с рекламой в мобилках уже прилично, но факт остаётся фактом, и об этом говорит Вадим.
В докладе рассматриваются два (а на самом деле почти три) подхода к детектированию фрода.
Backgroundness — показ рекламы в фоновом режиме. Суть такого типа фрода — в его названии. То есть реклама есть, но пользователь ее не видит. Как ее искать? Все не очень сложно, но есть нюансы. Суть изначального метода состоит в поиске в потоке входящих запросов всех запросов от пары «приложение+пользователь», которые шлют запросы непрерывно. Вычисляются такие интервалы и делается анализ на реалистичность.
Например, на слайде ниже поток сигналов T1 с интервалом между сигналами t1 можеть быть достаточно длинным, часов 10, что почти наверняка говорит о том, что это фрод. Ведь пользователь не может смотреть на экран 10 часов без перерыва. Если собрать статистику по этому приложению, можно с высокой степенью вероятности вычислить негодяев. Но, как обычно, есть нюанс — метод зависит как минимум от двух параметров, и оба из них вычисляются эмпирически.

Можно сделать проще? Оказывается, что можно опираться только на значение T (период непрерывного испускания сигнала) и анализировать интервалы между соседними отрезками времени (в нашем примере — искомый интервал между T1 и T2. Если в течение суток нет реалистичного перерыва (допустим, 6 часов), то, скорее всего, что-то пошло не так. В итоге при большом числе измерений от одного приложения точность метода растет.
Второй метод — Entropy Score. Поиск негодяев через аномальную энтропию. Чтобы стало понятнее, рекомендую предварительно почитать вики. Метод строится на последовательном численном анализе поведения пользователей и приложений. Вычисляется Entropy Score, за счет большого числа измерений определяется допустимый интервал значения этого параметра — когда с высокой степенью вероятности поведение приложения и пользователя являются реальными — а все остальные приложения подвергаются анализу.
Чуть более сложный метод используется и в IPONWEB в качестве дополнения к первому. Он позволяет поймать приложения, у которых небольшое число пользователей, даже несмотря на то, что непрерывного потока запросов нет. В качестве примера приводятся приложения для искусственного просмотра рекламы.
Третий метод не выделен явно. В нем анализируется большое число запросов с одного устройства. По сути, это аналог бота в вебе. Так что если вернуться к началу разговора, то Вадим немного лукавил, когда говорил, что методы анализа фрода в вебе не подходят.

В итоге за счет применения комбинации методов идентификации фрода ребята из IPONWEB отфильтровывают более 15% трафика. Очень солидный показатель с учетом общего числа запросов. Все методы — вероятностные, и всегда есть вероятность ошибки.
Диалог на эту тему ведется постоянно, когда в результате анализа режутся хорошие приложения, и поэтому система постоянно настраивается и корректируется. Тем не менее, надо понимать, что плохой трафик все равно остается. Возвращаясь к вопросу применения тех или иных методов в вебе и мобильных приложениях, Вадим отметил, что в целом ряде случаев ничего не мешает комбинировать их и получать хорошие результаты.
Смотреть видео
Если эта тема заинтересовала, то можно полистать ссылки ниже или просто погуглить термины, которые упоминает Вадим. Единственное, что немного раздражает — львиная доля инфы на эту тему представляет собой полурекламные статьи в обмен на почту от команд, которые занимаются как рекламой, так и борьбой с фродом.
- Доклад с Highload++ 2016 про фрод в вебе.
- Статья про типы фродов, которые досаждают все маркетологам.
- Серия статей про определение фродов по кликам.
- Seven Things You Should Know About In-App Fraud.
- Еще про фрод в мобильных приложениях.
Максим Лапшин (Erlyvideo). Делаем свою прошивку для IP-камеры на Rust
Макс — постоянный участник айтишных мероприятий, член программного комитета Highload++, автор очень быстрых и производительных решений для стриминга видео, которыми пользуются по всей планете, знаток erlang’a и просто отличный спикер. Его рассказ не вошел в тройку лучших, но послушать его обязательно надо — хотя бы потому, что его компания — одна из немногих в России успешно продвигает свой программный продукт на мировом рынке.

Непосредственно про стриминг и его нюансы Макс рассказывал на прошлых конференциях. В этот раз речь шла о том, как поменять софт на IP-камерах, как появился в этой истории Rust, и что из этого вышло. В докладе две части: первая — непосредственно про специфику работы с IP-камерами, вторая же посвящена Rust’у и его особенностям.
Несмотря на то, что IP-камеры широко распространены, дешевы, а аппаратная платформа с каждым годом становится все надежнее, софт для IP-камер оставляет желать лучшего. То есть вместе с камерой вы получаете софт 10-12 летней выдержки со всеми дефектами, отсутствием фич, а главное — невозможностью вносить изменения. В итоге разумнее всего написать свой софт, чтобы получить набор нужных фич и снизить сложность работы с устройством. Кстати, вариант сделать свою камеру тоже был — но от него отказались ввиду дороговизны и длительности, а также необходимости работать с уже существующими камерами, которых миллионы.
По сути, IP-камера является компьютером с процессором, памятью и прочими узлами, а значит и работать с ней можно, например, по аналогии с мобилками. Так же, как и в мобилках, здесь есть куча вариантов исполнения внутреннего программного обеспечения: где-то что-то можно писать, где-то только читать, есть разный U-boot (мощный загрузчик с кучей нужных для заливки функций) с разным софтом для перезаписи, есть большой набор различных шлейфов, щипцов и паяльников. Ну и, как следствие, — вылезают все прелести перепрошивки вашего любимого андроида: скакнуло питание — камера превратилась в кирпич, ошиблись в прошивке — снова кирпич. Благо, стоимость такого «кирпича» на текущий момент в пределах десяти долларов за штуку.
Чтобы облегчить себе жизнь, можно, как только удается добыть документацию на камеру и взломать ее, положить на нее софт, позволяющий производить дальнейшее обновление более привычным способом.
После сборки можно смело приступать к прошивке. Оказывается, что то, что вы раньше считали «зоопарком» технологий, — детский лепет по сравнению с тем, когда речь идет о камерах. Различные версии ядра, библиотек, SDK — абсолютная норма для них. Нормой же следует считать полное отсутствие возможности погонять тесты без заливки на камеру, жесткую нехватку места (8 мегабайт, ага), а также постоянную работу с железом и точное управлением памятью. Подытожим — камера очень интересный и одновременно дешевый прибор (можно смело экспериментировать и превращать камеры в кирпичи), с которым можно очень неплохо взаимодействовать, достигая свои цели.
Вторая часть рассказа всецело отдана Rust’у и его особенностям. Внимательный слушатель обязательно отметит для себя причины, по которым был выбран именно Rust, а не старый добрый С.
Следующие два слайда демонстрируют результаты, которые были достигнуты при использовании этого пока не очень распространенного языка для работы с железом.


Детально останавливаться не будем, отметим только, что Макс очень доходчиво объясняет любителям хайпа, что за все надо платить, и Rust — не исключение. В заключение отмечается, что, несмотря на внешнюю сложность, использовать для полу-embedded систем Rust можно, и это свежо и прикольно, хоть и придется немного переформатировать свой мозг.
От себя заметим, что многие вещи, о которых говорит Макс, характерны для разработки большинства встраиваемых систем. Если вы нацелились на это направление — обязательно послушайте.
Смотреть видео
Несколько менеджерских докладов Макса про его продукт и компанию:
- https://www.youtube.com/watch?v=xKsj3Av1ITE — рассказ о том, как сделать небольшую прибыльную компанию в сфере стриминга видео.
- https://www.youtube.com/watch?v=8qdo-HnXBJ8 — интервью с Максом на РИТ 2017.
- https://www.youtube.com/watch?v=Q29TKg_3xvo — как программисту вырастить свою компанию.
Алексей Вовченко (Luxoft) BigПочта: как мы строили DataLake в Почте России
Не знаю, как вам, но лично нам рассказов про айтишную составляющую эпического монстра и героя шуток-прибауток в лице Почты России (ПР) не попадалось. Рассказ Алексея — захватывающая история взлетов, падений и не всегда удачных экспериментов, изрядно сдобренная техническими деталями и нюансами тех или иных технологий и решений.
Начав с грустной истории про то, как в далёком 2012 посылка Алексея месяц пропадала где-то без возможности понять, где она, спикер начал шаг за шагом рассказывать о том, как видоизменялась и мутировала инфраструктура ПР как в части софта, так и в части выполняемых бизнес-операций для того, чтобы и вы, и сотрудники ПР сейчас могли выполнять эту и другие задачи.

ПР — Bigdata однозначно. 2КК отправлений в сутки. 200-400КК событий в сутки. 47К отделений по всей стране. Добавьте к этим цифрам сложность набора параметров, которые сопутствуют каждому отправлению. А ещё добавьте к этому финансовую информацию про продажу открыток, выдачу пенсий и приём платежей и переводов.
Очевидно, что обычная СУБД и система хранения не справятся. Начали искать решение, но по старой доброй традиции не всё предусмотрели изначально. Сначала взяли за основу Exadata+OracleBI, сделали прототип. Всё работало замечательно, но в момент, когда решили изменить масштаб до размеров страны, система начала тормозить, ввиду того, что на неё возложили все возможные и невозможные функции. «Тормозить» — в моменте напряженных периодов работы ПР, задержка по доставке данных могла достигать 5 (!) дней. Не очень быстро, да? Решение признали нерабочим, а в команду прилетела новая задача — всё то же самое, но лучше, быстрее и без оракла, только на открытом программном обеспечении. В итоге на арену вышли Hadoop, Kafka, Hive, Pentaho.
И сразу же следует совет — не надо делать ETL на Hive через map-reduce (хотя бы потому, что Hive не очень любит join-операции, а человечество давно придумало TEZ, а Hive с ним в сотни раз быстрее выполняет операции).
Дальше — больше. Данные надо отдавать и делать это быстро. Ночью кластер обсчитывает данные за прошедшие сутки, днём же его можно смело подгрузить другими операциями, например, закэшировать витрины данных в Spark SQL-сервер и отдавать их в Pentaho. Но под нагрузкой (47 тысяч отделений вместо 20 аналитиков) это снова не взлетело.
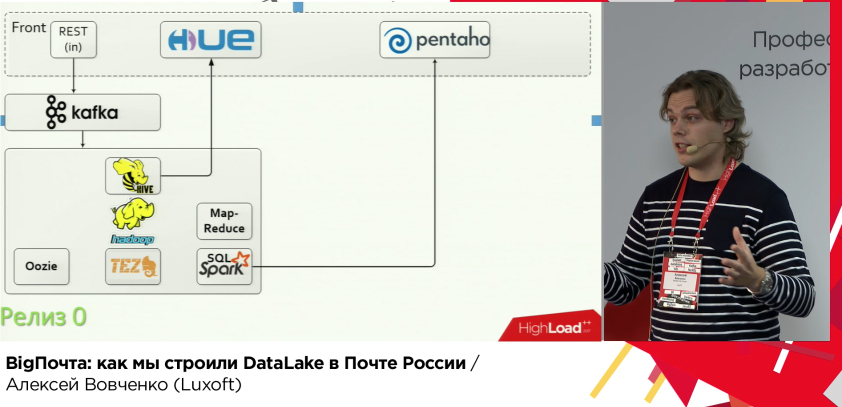
Начали искать SQL-решение с возможностью работы с HDFS и способностью работать с большим числом пользователей и выполнять тяжелые OLAP-запросы. Попробовали почти всё, что есть на рынке. Экзотику не смотрели по вполне себе очевидным причинам. В итоге выиграла Vertica (да-да, правило про open-source было принесено в жертву хорошему решению задачи). В итоге таки достигли нужного эффекта — отчётность формируется исправно и быстро.
Следующая задача — доступ к данным по ключу (операции по конкретному отправлению) — по id из 100 млрд. записей выбрать 10-100. Выбирали между Apache HBASE и Cassandra с победой второй по скорости, плюс Spark и Cassandra вместе очень хорошо дружат.
Дальше ещё больше. «А пусть это всё будет в реальном времени», — попросил заказчик. После некоторых экспериментов выбрали Spark Streaming. А kafka и cassandra и так могут real-time.
Всё бы ничего, но теперь упёрлись в производительность фронтов, Pentaho, Spark SQL Thrift, Spark Streaming. Решение для всех, кроме Streaming’a было найдено в применении Docker. А вот Streaming вынесли вообще из общего hadoop-кластера с свой маленький hadoop-кластер.
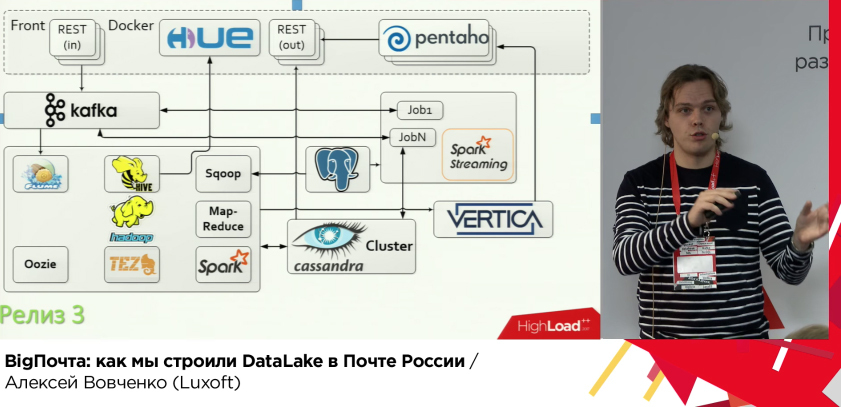
А ещё ребята попробовали Yandex Clickhouse, Flink (kafka -> hdfs) прикрутили для решения всяких-разных задач.
В продолжение Алексей таки рассказал, каким образом данные путешествуют по этому монстру, и что с ними происходит. А также, как это всё размещается на железе. Детально останавливаться не буду — лучше слушать, чтобы не пропустить ни одной мелочи.
В итоге получилась единая инфраструктура, которая решает огромное количество самых разных задач.
В завершение Алексей советует никогда не останавливаться на достигнутом, искать новые классные инструменты и не бояться их применять для решения своих задач. Решение продолжает развиваться, технологии и подходы пилотятся, а наши с вами посылки всё лучше и лучше отслеживаются.
Смотреть видео
Слушается на одном дыхании, интересные вопросы и ответы. 3 года работы, за которые команда выросла с 4 до 35 человек, а система — в сотни раз, уложились в 40 минут, и это прекрасно, хотя для многих из нас такие сроки и возможности, увы, недоступны. Многие из вас наверняка вспомнили микросервисы, подзадачность, шины данных и прочие способы снизить сложность комбайна ПР, наверняка подумали про то, сколько это всё стоило, но, как говорится, «что выросло, то выросло». С моей точки зрения отличный рассказ для тех, кто так или иначе проектирует и строит bigdata-системы и системы аналитики.
Любознательным ниже картинка с списком того, что звучало в докладе.

Александр Христофоров (Одноклассники). Дешевле, надёжнее, проще. Хранение петабайтов видео и фото в ОК
Одноклассники — безусловно в топе самых посещаемых порталов Рунета с огромным количеством контента. Ребята часто рассказывают (в том числе и на предыдущих конференциях РИТ++ и Highload++), как у них что устроено внутри, в этот раз они решили приоткрыть завесу тайны над их способом хранения фотографий и видео.

ОК, как любая современная соцсеть использует в работе огромную кучу разнопрофильного контента. Свои петабайты ОК достаточно долго хранил на самодельном хранилище — OBS (B Blob) — распределено по нескольким датацентрам, надёжно пишут по трём репликам в разных датацентрах одновременно, реплицируя не доехавшие данные. Всё это хранилось на 18К дисков вплоть до 2016 года. Видео-платформа очень неплохо развивалась, в итоге ОК получил прирост !петабайт! в месяц. В 2013 всего был петабайт, а по прогнозам на 2017 должно было стать 25 петабайт, при этом по железу рост был не такой стремительный, т.к. объем дисков рос. Увы, но бесконечно расти по железу нет возможности. Плюс с ростом дисков растёт время реплики и восстановления копий. Ну и просто хотелось сделать лучше.
Начали изобретать решение. Ясно, что терять надёжность нельзя, но при этом надо экономить место и стоимость. Первое, что пришло в голову, уменьшить число реплик с трёх до двух. Потом думали про зеркала, про XOR, но всё это позволяло спокойно умереть только одному винту из комплекта. Попробовали код Рида-Соломона, но оказалось, что при больших нагрузках и потерях одного ДЦ, система не может гарантировать доступность контента для пользователя, а чтобы это произошло, необходимо иметь многократный запас по мощности. В целом — схема работает. Но, не только в ПР постоянно думают, как улучшить то, что казалось бы и так работает.
Данные разделили на 10 блоков. Положили пополам в два ДЦ, в третий положили XOR и в дополнение положили в каждый ДЦ коды коррекции от Рида-Соломона. А в третий XOR от кодов коррекции. Для кодов коррекции используется алгоритм Even-odd. В итоге такая конфигурация позволяет при потере ДЦ восстанавливаться через XOR через два других ДЦ, а если же отказывает много дисков — опять XOR, но уже через чуть большее количество дисков.
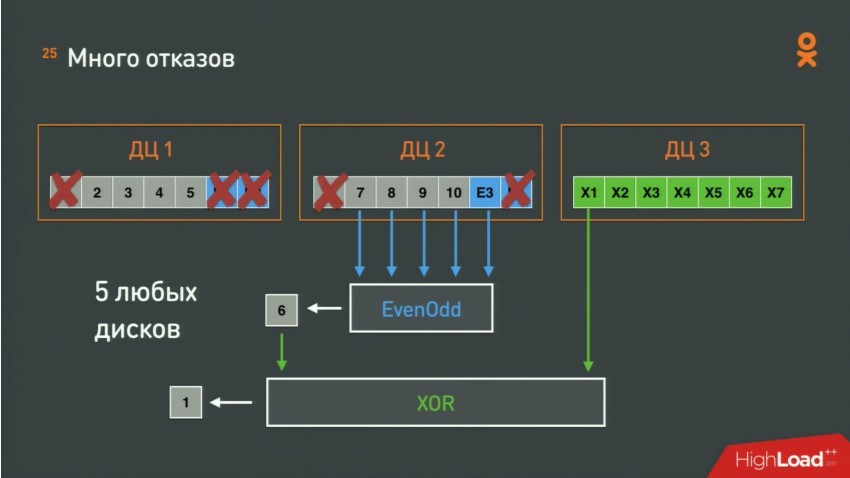
Казалось бы, всё выглядит круто и можно терять аж по 5 винтов за раз, НО по доброй айтишной традиции есть нюанс — схема работает только тогда, когда все блоки данных и блоки коррекции записаны. Если какого-то блока не хватает — данные пропали. Как исправить? Писать в три ДЦ, ждать, пока запишутся данные и уже после этого пересчитывать коды, раскладывать файлики и удалять ненужное. Явно что-то не так с эффективностью. На помощь пришёл старый добрый OBS. В него пишут, ждут пока запишется и уже после этого перекладывают и пересчитывают.
Дальше речь идёт о том, как это всё реализовано на Java c использование самописной библиотеки one-nio с удобным набором функций и API, в том числе и для работы с хипом. Много операций делается в хипе. Вот что бывает, если хорошо программировать на Java.
А как же диски? Они ведь умеют умирать медленно или плавно деградировать. В итоге диски стараются максимально изолировать. По факту сейчас — один диск — один элемент кластера со своим мониторингом, статистикой, своим тред-пулом и пр. Т.е. если умирает или начинает тупить один диск, то это никак не мешает остальным дискам на сервере продолжать работать. Выглядит круто. Но ОК были бы не ОК, если бы не пошли дальше. Ребята отказались от файловой системы. Действительно, если данные лежат в блобах и доступ всё равно идёт по смещению, зачем тратить силы и время на управление и поддержание файловой системы — диск стал одним большим файлом.
Далее Александр рассказывает про решение задачи неравномерного заполнения дисков. Несмотря на всю сложность операции выравнивания заполненности, задача решается через балансировку данных. С более заполненного диска данные переливаются на менее заполненный. Здесь появилась другая проблема. Если диски активно задействованы в копировании и восстановлении — скорость доступа к пользовательским данным серьезно падает. И здесь нашлось решение — io scheduler. Все «читатели» получают свой приоритет и не толкаются, а смиренно ждут, пока освободится диск.
Как хранить — понятно, а как читать и управлять всей этой махиной? Про это заключительный раздел доклада.
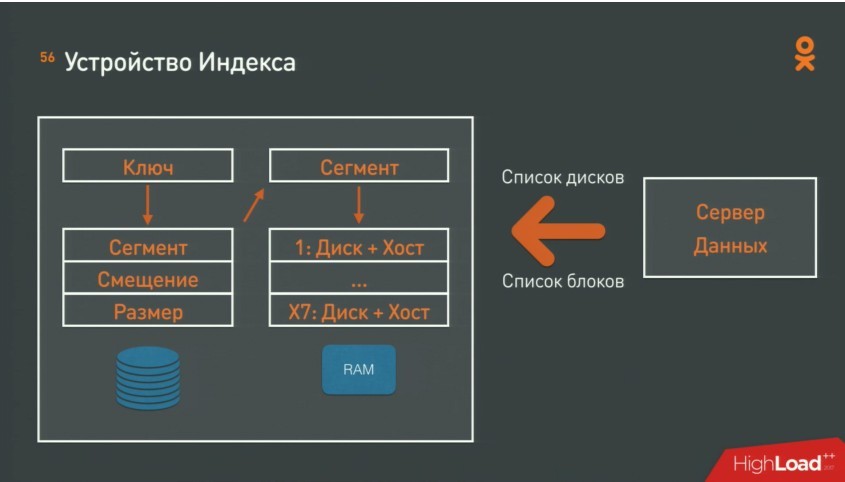
Основная задача — поиск координат хранения данных в огромной массе блоков. Для этого используется индекс — Cassandra+Java-приложение, которые отвечают на вопрос — как по ключу найти данные- сегмент+смещение+размер. А вторым запросом по сегменту достаётся диск и хост. Система управления всем этим хозяйством в результате эволюции выродилась в набор простых правил, которые непрерывно выполняются на серверах.
В итоге — «Система эксплуатируется год. Самый главный результат — 19 петабайт места и 175 серверов мы сэкономили, и всё это при доступности 99,999%». Дешевле, надежнее, проще.
Смотреть видео
Отдельно обратим внимание, что созданная система хранения стала второй в ОК, т.к. OBS эксплуатируется по-прежнему, хоть и под меньшей нагрузкой. Строя новый мост, на старом по-прежнему перекладывают асфальт, ага. Многие подходы, о которых говорит Александр могут быть полезными, даже если вы не обладаете столь обширными запасами котиков и прочего контента.
Также очень рекомендую послушать/почитать ещё два доклада на эту тему от Badoo и Dropbox:
- Артём Денисов из Badoo про эволюцию хранилища фотографий.
- Слава Бахмутов про систему хранения Dropbox.
Пара интересных рассказов от самих ОК:
- Никита Духовный про балансировку и отказоустойчивость.
- Олег Анастасьев про систему управления датацентром.
- Как в ОК работают с распределёнными системами от Олега Анастасьева.
На прощание традиционно предлагаем подумать, каким скрываемым от общественности опытом уже пора поделиться, и отправить заявку на выступление нашему программному комитету.